Home
/ Parquet Data - Storing Data As Parquet Files Scala Data Analysis Cookbook : This connector was released in november 2020.
Parquet Data - Storing Data As Parquet Files Scala Data Analysis Cookbook : This connector was released in november 2020.
Parquet Data - Storing Data As Parquet Files Scala Data Analysis Cookbook : This connector was released in november 2020.. The same columns are stored together in each row group: Map, list, struct) are currently supported only in data flows, not in copy activity. And who tells schema, invokes automatically data types for the fields composing this schema. It maintains the schema along with the data making the data more structured to be read and process. In the sample data, expanded parquet files.
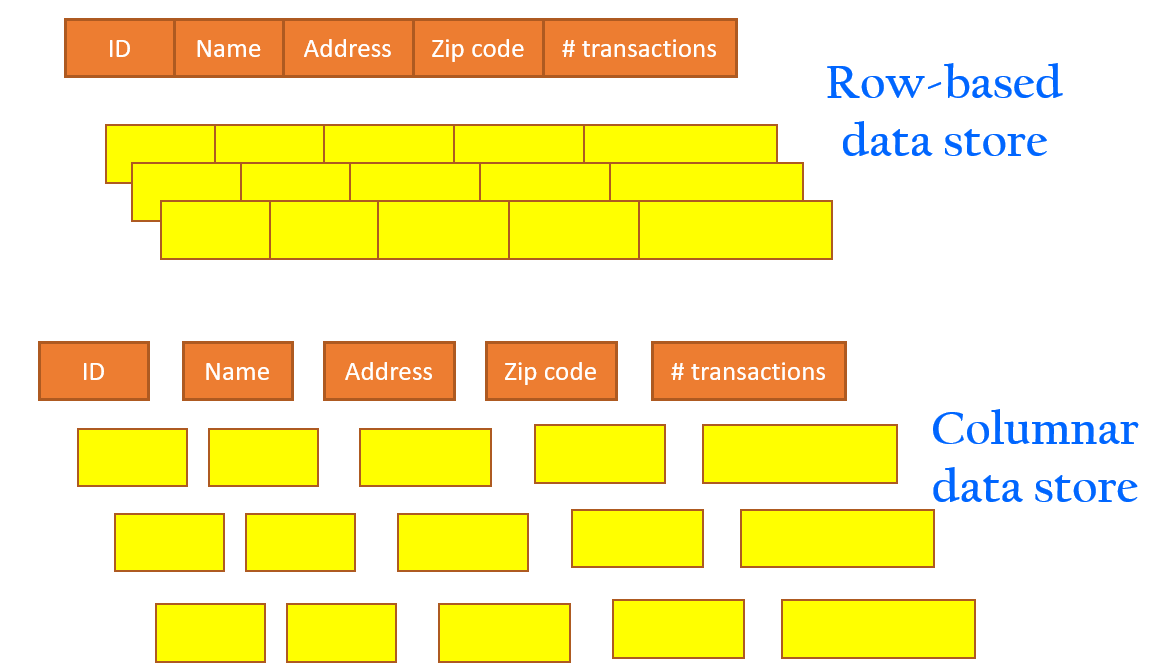
The same columns are stored together in each row group: Parquet operates well with complex data in large volumes.it is known for its both performant data compression and its ability to handle a wide variety of encoding types. Parquet is an open source file format built to handle flat columnar storage data formats. Parquet is a columnar format that is supported by many other data processing systems. Spark sql provides support for both reading and writing parquet files that automatically preserves the schema of the original data.
Big Data File Formats Blog Luminousmen from iamluminousmen-media.s3.amazonaws.com Both formats are natively used in the apache ecosystem, for instance in hadoop and spark. The parquet format's logicaltype stores the type annotation. Parquet, adls gen2, etl, and incremental refresh in one power bi dataset. Parquet is an open source file format built to handle flat columnar storage data formats. Our drivers and adapters provide straightforward access to parquet data from popular applications like biztalk, mulesoft, sql ssis, microsoft flow, power apps, talend, and many more. Parquet is a columnar storage format that supports nested data. When reading parquet files, all columns are automatically converted to be nullable for compatibility reasons. The drawback again is that the transport files must be expanded into individual avro and parquet files (41% and 66%).
To use complex types in data flows, do not import the file schema in the dataset, leaving schema blank in the dataset.
Parquet detects and encodes the same or similar data using a technique that conserves resources. Apache parquet is built to support very efficient compression and encoding schemes. Snappy compressed files are splittable and quick to inflate. The annotation may require additional metadata fields, as well as rules for those fields. A year ago, i was developing a solution for collecting and analyzing usage data of a power bi premiu m capacity. For transformations that support precision up to 38 digits, the precision is 1 to 38 digits, and the scale is 0 to 38. Parquet files were designed with complex nested data structures in mind. This connector was released in november 2020. Pyspark sql provides methods to read parquet file into dataframe and write dataframe to parquet files, parquet() function from dataframereader and dataframewriter are used to read from and write/create a parquet file respectively. Decimal value with declared precision and scale. The parquet connector is the responsible to read parquet files and adds this feature to the azure data lake gen 2. Optimized for working with large files, parquet arranges data in columns, putting related values in close proximity to each other to optimize query performance, minimize i/o, and facilitate compression. We believe this approach is superior to simple flattening of nested name spaces.
Decimal value with declared precision and scale. In the sample data, expanded parquet files. Each page contains values for a particular column only, hence pages are very good candidates for. Both formats are natively used in the apache ecosystem, for instance in hadoop and spark. Parquet, adls gen2, etl, and incremental refresh in one power bi dataset.
Columnar Data Apache Arrow And Parquet With Julien Le Dem And Jacques Nadeau Software Engineering Daily from i1.wp.com There is an older representation of the logical type annotations called convertedtype. This results in a file that is optimized for query performance and minimizing i/o. Parquet is built from the ground up with complex nested data structures in mind, and uses the record shredding and assembly algorithm described in the dremel paper. And who tells schema, invokes automatically data types for the fields composing this schema. Use surveymonkey® market research solutions to collect data, on demand. To use complex types in data flows, do not import the file schema in the dataset, leaving schema blank in the dataset. A common data model data type is an object that represents a collection of traits. For transformations that support precision up to 38 digits, the precision is 1 to 38 digits, and the scale is 0 to 38.
The data for each column chunk written in the form of pages.
Parquet complex data types (e.g. Each row group contains data from the same columns. Apache parquet data types map to transformation data types that the data integration service uses to move data across platforms. The parquet connector is the responsible to read parquet files and adds this feature to the azure data lake gen 2. Use surveymonkey® market research solutions to collect data, on demand. All data types should indicate the data format traits but can. Parquet, adls gen2, etl, and incremental refresh in one power bi dataset. Parquet is an open source file format available to any project in the hadoop ecosystem. Both formats are natively used in the apache ecosystem, for instance in hadoop and spark. Parquet operates well with complex data in large volumes.it is known for its both performant data compression and its ability to handle a wide variety of encoding types. It maintains the schema along with the data making the data more structured to be read and process. This column represents parquet data type. Scale must be less than or equal to precision.
Decimal value with declared precision and scale. Market research services that scale to meet your needs. Data types in apache parquet versions: The parquet format's logicaltype stores the type annotation. There is an older representation of the logical type annotations called convertedtype.
How Fast Is Reading Parquet File With Arrow Vs Csv With Pandas By Tirthajyoti Sarkar Towards Data Science from miro.medium.com It maintains the schema along with the data making the data more structured to be read and process. For more details, visit here. Snappy compressed files are splittable and quick to inflate. The data for each column chunk written in the form of pages. It is compatible with most of the data processing frameworks in the hadoop environment. This column represents parquet data type. For further information, see parquet files. There is an older representation of the logical type annotations called convertedtype.
So, data in a parquet file is partitioned into multiple row groups.
So, data in a parquet file is partitioned into multiple row groups. This results in a file that is optimized for query performance and minimizing i/o. Apache parquet defines itself as: For further information, see parquet files. There is an older representation of the logical type annotations called convertedtype. We have a list of boolean values say 0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1 (0 = false and 1 = true) this will get encoded to 1000,0000,1000,0001 where 1000 => 8 which is number of occurences of. In parquet, it is used for encoding boolean values. Popular workflow & automation tool integrations Use surveymonkey® market research solutions to collect data, on demand. The same columns are stored together in each row group: This allows clients to easily and efficiently serialise and deserialise the data when reading and writing to parquet format. Parquet format also defines logical types that can be used to store data, by specifying how the primitive types should be interpreted. Parquet is a binary format and allows encoded data types.
Each row group contains data from the same columns parquet. Parquet files were designed with complex nested data structures in mind.